第1回 機械学習とは?

AIブームと言われて既に久しいですが、日本のAI普及率は伸び悩んでいるのが現状です。
当社では過去4年間、主に社員向けに機械学習の勉強会を開催してきましたが、我々も微力ながら日本のAI普及に貢献したいということで、これを社外の方にも公開していくこととなりました。今回はその1回目となります。
本セミナーが対象としているのは、今後AIに取り組んでいきたいと考えているAIビギナーの方です。数学が苦手な人にも理解しやすいように、機械学習の理論には深く立ち入らず、実装に重点を置いたセミナーとしていく予定です。
初回はイントロダクションとして、「機械学習とは?」と題して、AI全般の概要について解説します。2回目以降は、毎回異なるテーマで、AIの具体的な実装方法の解説を行っていきます。本セミナーで取り上げるのは主として画像認識、自然言語処理などですが、回帰、分類、クラスタリングといった、機械学習の主要なタスクをまんべんなく取り上げていく予定です。
それでは、一緒にAIについて勉強していきましょう。
目次
- AI技術と機械学習
- 第1次AIブーム
- 第2次AIブーム
- 第3次AIブーム
- ルールベースと機械学習の違い
- モデルと特徴量
- 機械学習はルールベースとどう違うのか?
- 機械学習の定義
- そもそも機械学習とは何か?
- 機械学習の種類
- 学習方法の違いによる分け方
- タスクの違いによる分け方
- アルゴリズムの例
AI技術と機械学習
人工知能(AI)という言葉が初めて使われたのは1956年にアメリカで開催されたダートマス会議においてです。この会議から人工知能という言葉が定着し、1つの研究分野になっていったと言われています。
AI技術には過去2度のブームがありましたが、いずれも世の中の期待外れに終わってしまいました。現在は第3次AIブームの真只中ですが、第3次AIブームのキーテクノロジーは機械学習です。
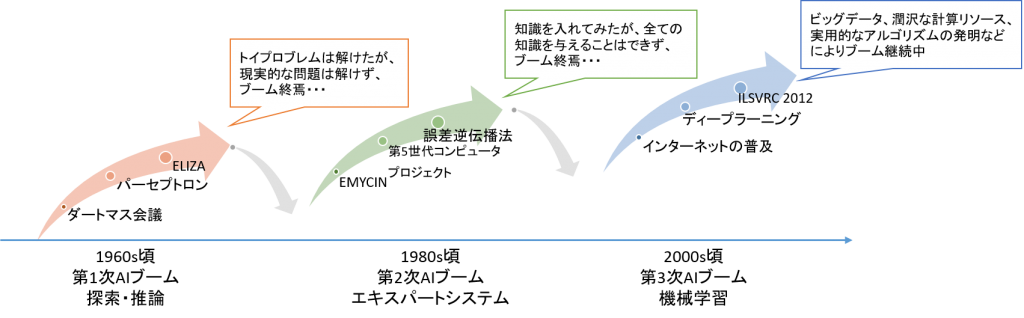
第1次AIブーム
第1次AIブームでは、「探索と推論」を中心に研究されていました。データの集まりから条件に合うものを探したり、ルールを統合して矛盾の無い答えを見つけ出すというものです。しかし、決まった条件下での簡単な問題(トイプロブレム)しか解けず、ブームは衰退してしまいました。
第2次AIブーム
第2次AIブームでは「知識」をテーマにした研究が実施されていました。知識の内容を的確に表現する・蓄積する「エキスパートシステム」と呼ばれるものです。しかし、常識や暗黙知まで考慮するとインプットすべき情報が膨大すぎて、全てを記録する事は不可能だと判明し、最終的にこちらもブーム終焉となりました。
第3次AIブーム
現在も続く第3次AIブームではビッグデータにより機械学習が実用化され始めたことや、GPUなどの計算リソースの進歩から深層学習の学習効率が向上したことから再びAIが注目され始めました。
画像認識の国際コンテスト「ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 2012」で深層学習を用いたモデル「AlexNet」が圧勝したことや、2015年にGoogle DeepMindによって開発されたコンピュータ囲碁プログラム「AlphaGo」が初めてプロ囲碁棋士に勝利したことなどからも期待が高まっています。
機械学習はAI技術の一つにすぎませんが、画像認識や音声認識など様々な技術の基盤となっている重要な技術です。また、機械学習の中にもさらに様々な技術があり、近年注目されている深層学習は機械学習の一種となります。

ルールベースと機械学習の違い
モデルと特徴量
画像認識や音声認識、自然言語処理などではデータを機械(主にコンピュータ)が処理します。データを入力して何かしらの結果を出力するものをモデルと呼ぶことにします。また、モデルにデータを入力して結果を出力する過程を推論と言います。例えば画像認識モデルであれば、画像データを入力して推論を行い、認識結果を出力します。そして、その認識結果が人間並かそれ以上の精度であれば、それは良いモデルと言えるでしょう。より良いモデルを作るということは第一次AIブームの頃から変わらずに追求されている課題の一つです。
さて、モデルに入力するデータですが、生のデータをそのまま入力しても良い結果が得られないことがほとんどです。そこで人間が試行錯誤しながら生のデータを加工して、特徴量と呼ばれる有効な入力データを作成するという作業が必要となります。これは特徴量エンジニアリングとも呼ばれ、いわば職人芸のような作業で、データやタスクに関する深い知識が求められます。適切な特徴量を見つけるということも長らく追求されてきた課題の一つです。

- 特徴量エンジニアリングの例
- 画像認識
- エッジを強調するフィルターを演算した結果
- 顔の各部位(目、鼻、口など)の座標
- 音声認識
- 音声の各周波数成分
- ローパス/ハイパスフィルターを演算した結果
- 自然言語処理
- 単語の出現頻度
- N-gram
- 画像認識
機械学習はルールベースとどう違うのか?
一般的にモデルには調整可能なパラメータが含まれています。ルールベースによるモデルの場合、そのパラメータの値を具体的に決定するのは人間です。「特徴量の値がこれくらいの時は推論結果がこうなるように」といった具合に人間が一つ一つ考えてパラメータを調整します。つまりルールベースによるモデルの場合は、特徴量もモデルの詳細も人間が決める必要があります。

一方、機械学習によるモデルの場合、機械自身が特徴量からそれらに潜むパターンを学習してパラメータの値を決定することができます。ルールベースのモデルとは異なり、人間がすべきなのは適切な特徴量を用意することだけです。

さらに深層学習によるモデルの場合、人間は特徴量すら用意する必要がありません(もちろん用意しても良いです)。面倒な特徴量エンジニアリングから解放されるのです。データを与えるだけでモデルの内部で自動的に特徴量を獲得し、推論することができます。これは非常に画期的なことであり、深層学習が現在のように注目を集めている理由もここにあります。

ルールベースと機械学習、深層学習の違いをまとめると次の表のようになります。

機械学習の定義
そもそも機械学習とは何か?
ここで、そもそも機械学習とは何なのかという定義について触れておきましょう。機械学習の定義は明確に定義されておらず、人によって異なるため、いくつかの定義を紹介します。まず、Wikipediaと人工知能学会による大雑把な定義は以下のようなものです。
人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法のこと[1](Wikipedia)
観測センサーやその他の手段で収集されたデータの中から一貫性のある規則を見つけだそうとする研究[2](人工知能学会)
次に機械学習という言葉を作ったArthur Samuelによる定義を紹介します。
Arthur Samuel (1959)の定義
Field of study that gives computers the ability to learn without being explicitly programmed[3]
- 訳: 明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野
また、広く引用されている定義として、コンピュータ科学者Tom Michael Mitchellの定義もあります。
Tom Michael Mitchell (1997)の定義
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.[3]
- 訳: コンピュータプログラムが、ある種のタスクTと評価尺度Pにおいて、経験Eから学習するとは、タスクTにおけるその性能をPによって評価した際に、経験Eによってそれが改善されている場合である。
ここで「task(タスク)」とはモデリングのアルゴリズム、「performance measure(評価尺度)」とは精度、誤差率などの評価指標、「experience(経験)」とはデータセットのことを指します。
Tom Michael Mitchelの定義は少々堅い表現であるため、嚙み砕いて説明します。
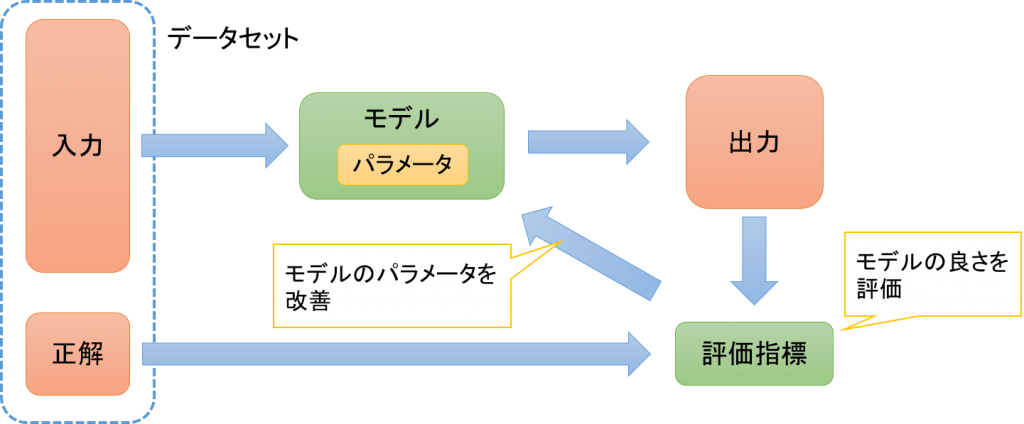
モデルには調整可能なパラメータが含まれていますが、通常、最初はランダムな値で初期化されています。このモデルにデータを入力すると何かしらの出力が得られます。
しかし、最初のうちはこの出力は正解から外れたいい加減な値になることがほとんどです。そこで、事前に何かしらの評価基準を決めておいて、モデルの出力値をデータセットに含まれる正解値と比較することで、モデルの出力値が正解値からどれだけずれているのかを測定します。このずれを測定することはつまり、モデルの良さを評価していることにもなります。モデルの出力値と正解値の間のずれが小さいほど良いモデルと言えます。
そして、このずれが小さくなるようにモデルのパラメータを更新すれば、モデルはより良いモデルになるはずです。データセットに含まれる様々なデータをモデルに入力してモデルのパラメータの更新を繰り返すことで、モデルの出力値と正解値の間のずれがどんどん小さくなり、そのデータセットに最適なモデルへと近づいていきます。
この一連の処理を人手によらず、機械が自ら行うことが機械学習なのです。
機械学習の種類
機械学習には観点によっていくつかの分け方があります。ここでは学習方法の違いによる分け方、タスクの違いによる分け方の2つを紹介します。
学習方法の違いによる分け方
機械学習を学習方法の違いで分けると教師あり学習と教師なし学習という学習方法に分けられます。ここでいう「教師」とは与えられる入力データに対する出力の「正解」のことをいいます。
- 教師あり学習(Supervised Learning)
⇒モデルの学習時に「正解」が予め分かっている
- 教師なし学習(Unsupervised Learning)
⇒モデルの学習時に「正解」は分からない
教師あり学習はモデルの学習時に正解が与えられ、それを元に学習していく方法です。こちらは先ほど説明した、モデルの出力値と正解値を比較してパラメータを更新していく方法に相当します。教師あり学習は未知のデータに対する予測を行うのに適しています。
一方、教師なし学習はモデルの学習時に正解は与えられません。モデルは入力されたデータの特徴や構造を学習していきます。教師なし学習はデータに人手でラベル付けを行う「アノテーション」という作業が不要なため、低コストで学習できますが、正解が必要となるような学習には不向きです。
タスクの違いによる分け方
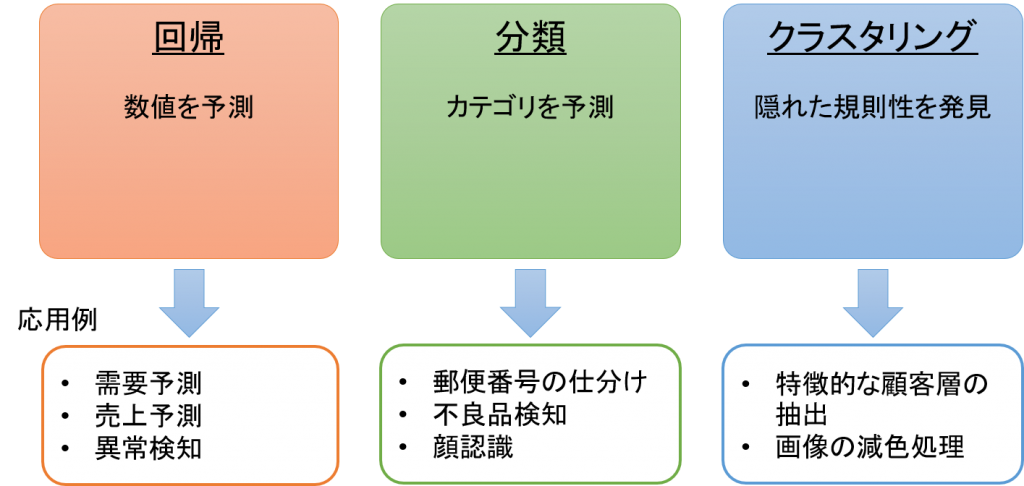
タスクの違いで機械学習を分類すると回帰、分類、クラスタリングに分けられます。
- 回帰(Regression)
⇒数値を予測する
- 分類(Classification)
⇒ラベル(クラス)を予測する
- クラスタリング(Clustering)
⇒データをある基準に従ってグループ化する
回帰は出力データが数値となるようなタスクです。つまり、モデルは入力されたデータから適切な数値を予測することが求められます。例えば人間の身長と体重は直感的にはある程度相関がありそうです。そこで身長のデータから体重を予測することを考えます。モデルに身長と体重のデータを与えて適切に学習させれば身長から体重を予測するモデルができます。これが回帰です。
ビジネスシーンでは需要予測や売上予測などが回帰タスクになります。
分類は出力データがラベル(クラス)となるようなタスクです。ラベルとはデータのカテゴリーのことで、分類タスクで用いるデータには各入力データにラベルがついています。例えば動物が写っている画像があったとき、その画像に写っているのが何の動物かを予測するなどが分類のタスクになります。
社会で実用化されているものとしては不良品の検知や顔認証などがあります。
クラスタリングはデータを何らかの基準に従ってグループ化するタスクのことです。クラスタリングは学習方法でいうと教師なし学習に分類されます。クラスタリングによって得られたグループをクラスターといいますが、各クラスターがどういったクラスターなのかを解釈するのは人間が行います。
マーケティングの市場分析における特徴的な顧客層の抽出や、画像の色数を減らしてデータを圧縮する減色処理などに用いられています。
世の中のタスクはこれらのどれかに帰着できる場合が多いです。
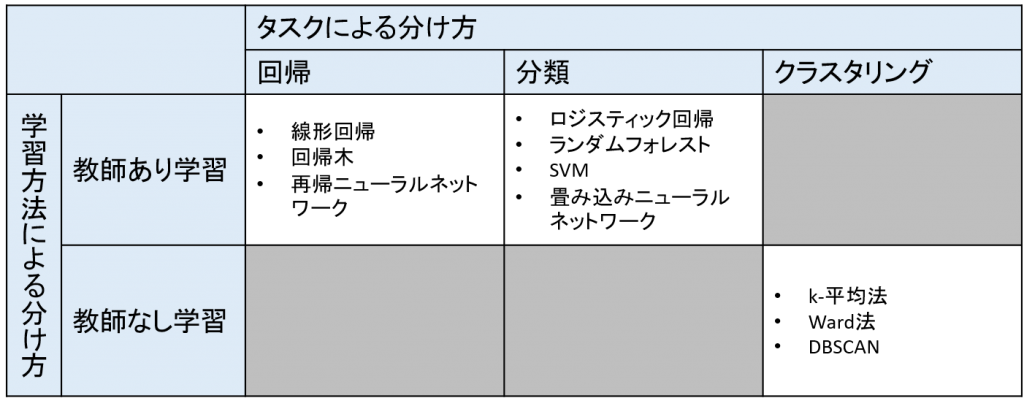
アルゴリズムの例
機械学習の学習方法とタスクの2通りの分け方を紹介しましたが、分けた先にもそれぞれに様々なアルゴリズムが存在します。代表的なものを以下の表にまとめました。ここでは各アルゴリズムの詳細には触れませんが、この内のいくつかは次回以降のセミナーで紹介する予定です。
今回は機械学習の概要をご紹介しました。次回からはより具体的な内容に入っていきます。まず最初に扱うのは画像認識です。画像認識の中にも様々なタスクがありますが、一般物体認識というタスクを紹介する予定です。
一般物体認識とは、画像中にある物体が何なのか予測し、その物体の一般的な名称を答えるタスクのことです。人間にとっては簡単なタスクですが、深層学習が登場するまでは機械にとって難しいタスクの一つでした。驚くべきことに深層学習によって、それが今や人間の認識精度を凌駕するところまで来ています。
最後までお読みいただきありがとうございました。それでは引き続き次回もよろしくお願いいたします。
出典
^ [1] Wikipedia, 機械学習 https://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92
^ [2] 人工知能学会 http://www.ai-gakkai.or.jp/whatsai/AIresearch.html
^ a b [3] Stanford Machine Learning http://holehouse.org/mlclass/01_02_Introduction_regression_analysis_and_gr.html

