第2回 一般物体認識
今回からいよいよ実装に入ります。内容は以前にハンズオン形式で行った一般物体認識のセミナーを元にしています。一般物体認識は、画像中の物体の位置を検出し、その物体の名前を予測するタスクで、画像認識のタスクの一つです。一般物体認識の概要については解説動画を作成しましたので、そちらをご覧ください。
今回の実装のソースコードはこちらからダウンロードできます。
目次
解説動画
ハンズオン概要
目的
本ハンズオンはクラウドAPIや、学習済みモデルを利用し、一般物体認識を行う簡単なアプリケーションを実装することで、AI技術を体感することが目的となっています。いくつかのアカウントは必要となりますが、ブラウザで実装できるため、環境構築は不要です。
実装内容
実装する処理は大きく分けて4つの工程があります。各処理の詳細については実装の項目で説明します。
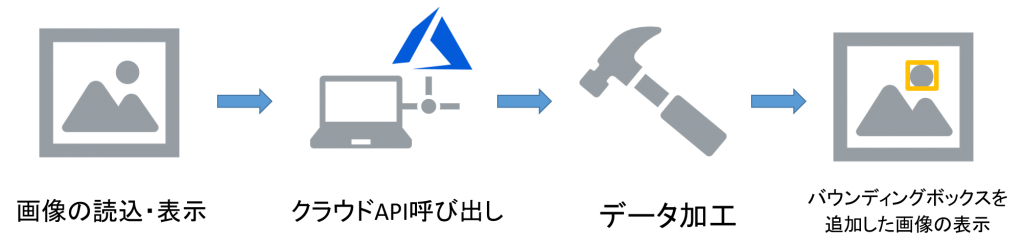
クラウドAPIについて
APIとはApplication Programming Interface(アプリケーション・プログラミング・インタフェース)の略でプログラムから外部のソフトウェアを操作するためのインターフェースのことです。クラウドAPIはクラウドサービスを呼び出すためのAPIのことを指します。
クラウドサービスでは既に大量のデータで学習済みのモデルが用意されています。そのため、クラウドAPIを利用することで、例えばクラウドサービスに画像を送信し、その画像の解析結果を取得することなどができます。このように、機械学習のモデルを自分で学習させずに学習済みのモデルを活用できるのが特徴です。その反面、精度を上げたり、細かいカスタマイズをしたりといったことはできません。

Microsoft Azure Cognitive services Computer Vision API
ここではMicrosoft AzureのCognitive services Computer Vision APIという画像認識を行うためのクラウドAPIを使用します。このComputer Vision APIに画像をアップロードすることで、
- 文章での表現
- タグ
- バウンディングボックス(認識対象を囲む四角形)
- わいせつ度
といった認識結果を表示してくれます。
より詳細な使用方法が知りたい方はAPIリファレンスがありますのでこちらをご参照ください。
準備
本ハンズオンでは以下のサービスのアカウントが必要になります。持っていない場合は事前に作成しておいてください。どちらも無料で作成できます。
Azure Cognitive Servicesのリソース作成
下記のリンクを参考にCognitive Servicesのリソースを作成してください。リソースを作成すると、エンドポイントURLとAPIキーが作成されます。これらはAPI呼び出し時に必要となるので、用意しておいてください。
Google Colaboratory
以下、Google公式によるColaboratoryの説明(下記リンク先より引用)
Colaboratory(略称: Colab)は、ブラウザから Python を記述、実行できるサービスです。次の特長を備えています。
- 環境構築が不要
- GPU への無料アクセス
- 簡単に共有
以下のリンクからGoogle Colaboratoryを開いてください。Google Driveからアクセスしても構いません。
Colaboratoryの基本的な使い方についてはリンク先の「はじめに」の説明を参考にしてください。
https://colab.research.google.com/notebooks/welcome.ipynb
このようなページが表示されればOK
使用する画像
画像は以下の画像を使用します。同じ画像を使用する場合は右クリックで保存して使用してください。他の好きな画像を使用しても構いません。

Google Colaboratoryに画像をアップロード
- Google Colaboratory画面右上の「接続」をクリック
- 画面左端の「ファイル」ボタンをクリック
- 「セッションストレージにアップロード」ボタンをクリック
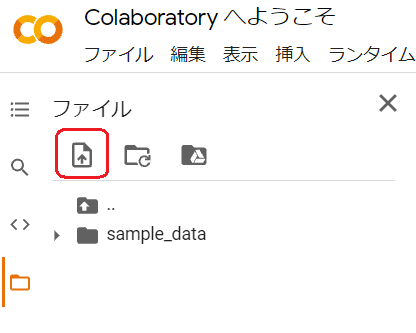
- アップロードする画像を選択
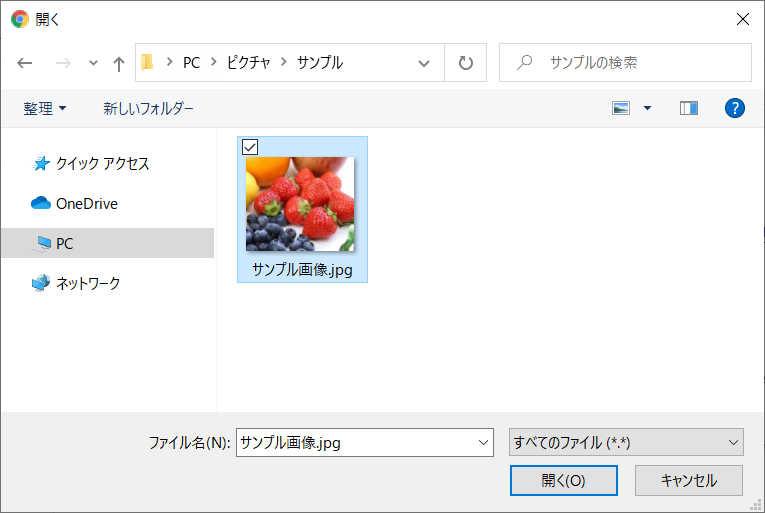
- アップロードした画像が表示されていればOK
実装
画像の読込・表示
アップロードした画像を表示してみます。
以下のコードをコピーするか、手で入力して実行してください。
※画像ファイルを右クリックし、「パスをコピー」でファイル名を取得出来る
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
# ファイル名をセット
filename = "/content/サンプル画像.jpg"
# Pillowライブラリで画像を表示
img = Image.open(filename)
plt.imshow(img)
plt.show()

実行後、画像が表示されればOKです。
クラウドAPI呼び出し
Computer Vision APIに画像データを送信(HTTP通信)します。
HTTP通信時には以下の情報を設定します。
- Azure契約時に発行したAPIキー
- 通信形式(バイナリ情報を指定)
- 画像データ(バイナリ)
- 取得する情報(バウンディングボックス)
リクエストのURLは以下のように設定します。{endpoint}に作成したエンドポイントを入れてください。
https://{endpoint}/vision/v3.2/analyze
import requests
import json
# Azure_キー
# MEMO:現在使用できません。AZUREの登録をしキーを再取得して下さい。
subscription_key = 'c2b16299c10946a28c7000b639190ecb'
# Azure_URL
# キーと同様AZUREの登録をしURLを再取得して下さい。
analyze_url = 'https://ai-seminar.cognitiveservices.azure.com/vision/v3.2/analyze'
# http通信の設定
headers = {'Ocp-Apim-Subscription-Key': subscription_key,
'Content-type':'application/octet-stream'}
params = {'visualFeatures': 'Description,Objects'}
# バイナリ形式で読み込み
with open(filename, 'rb') as f:
binary = f.read()
# http通信でデータの確認
response = requests.post(analyze_url, headers=headers, params=params, data=binary)
# リクエスト結果の確認
print(response)<Response [200]>
セルの実行後、<Response [200]>と表示されればOKです。
データ加工
リクエスト結果の中身を確認するため、response.json() を実行してみます。
response.json()以下のようなデータが出力されます。これはHTTPのレスポンスをJSONという形式で表示したものです。
{'description': {'tags': ['food', 'fruit', 'berry', 'fresh', 'arranged'],
'captions': [{'text': 'a pile of fruit', 'confidence': 0.437145471572876}]},
'objects': [{'rectangle': {'x': 2, 'y': 0, 'w': 126, 'h': 85},
'object': 'Fruit',
'confidence': 0.784,
'parent': {'object': 'Food', 'confidence': 0.792}},
{'rectangle': {'x': 137, 'y': 31, 'w': 72, 'h': 66},
'object': 'Strawberry',
'confidence': 0.511,
'parent': {'object': 'Fruit',
'confidence': 0.513,
'parent': {'object': 'Food', 'confidence': 0.515}}},
{'rectangle': {'x': 217, 'y': 42, 'w': 64, 'h': 61},
'object': 'Strawberry',
'confidence': 0.563,
'parent': {'object': 'Fruit',
'confidence': 0.568,
'parent': {'object': 'Food', 'confidence': 0.572}}},
・・・中略・・・
{'rectangle': {'x': 162, 'y': 135, 'w': 111, 'h': 106},
'object': 'Strawberry',
'confidence': 0.613,
'parent': {'object': 'Fruit',
'confidence': 0.615,
'parent': {'object': 'Food', 'confidence': 0.616}}}],
'requestId': '654f1b4e-26a0-46b2-ad48-f2d9f213c363',
'metadata': {'height': 272, 'width': 314, 'format': 'Jpeg'},
'modelVersion': '2021-05-01'}
そのままでは読みにくいのでこれを表形式に変換します。
import pandas as pd
# 表を作成
columns = ['name','x_start','y_start','x_end','y_end']
df = pd.DataFrame(columns = columns)
# 通信の結果からバウンディングボックスの情報を取得
objects = response.json()['objects']
# 認識した物体ごとにループ
for obj in objects:
# 要素抽出
name = obj['object']
h = obj['rectangle']['h']
w = obj['rectangle']['w']
x = obj['rectangle']['x']
y = obj['rectangle']['y']
x_e = x + w
y_e = y + h
# 表に追加
tmp_se = pd.Series([name, x, y, x_e, y_e], index=columns)
df = df.append(tmp_se, ignore_index=True)
df| name | x_start | y_start | x_end | y_end | |
|---|---|---|---|---|---|
| 0 | Fruit | 2 | 0 | 128 | 85 |
| 1 | Strawberry | 137 | 31 | 209 | 97 |
| 2 | Strawberry | 217 | 42 | 281 | 103 |
| 3 | Fruit | 0 | 36 | 38 | 153 |
| 4 | Strawberry | 72 | 54 | 159 | 133 |
| 5 | Strawberry | 20 | 96 | 107 | 172 |
| 6 | Strawberry | 235 | 89 | 314 | 194 |
| 7 | Strawberry | 112 | 112 | 190 | 202 |
| 8 | Strawberry | 162 | 135 | 273 | 241 |
表形式に表示されたらOKです。
表のnameは認識した物体の名称、x_start, y_start, x_end, y_endはそれぞれ、画像上の各バウンディングボックスの左端のx座標、上端のy座標、 右端のx座標、下端のy座標を表しています。
バウンディングボックス表示
PILのImageDrawを使って、画像にバウンディングボックスを重ねます。
from PIL import ImageDraw
import copy
# 画像のコピーを作成
copy_img = copy.deepcopy(img)
draw = ImageDraw.Draw(copy_img)
# バウンディングボックス書き込み
color = 'black'
for index, row in df.iterrows():
name = row['name']
gird = (row['x_start'], row['y_start'], row['x_end'], row['y_end'])
draw.rectangle(gird, outline=color)
draw.text((row['x_start'] + 5, row['y_start']),text = name, fill=color)
# 画面表示(サイズ調整有り)
size_rate = max(max(img.size) / 400, 1)
plt.figure(figsize=(8 * size_rate, 6 * size_rate))
plt.imshow(copy_img)
plt.show()
バウンディングボックスが追加された画像が表示されればOKです。
演習問題
①HTTP通信時に設定を変更して様々なデータを取得する
以下の表を参考に、visualFeaturesのタグを変更して、バウンディングボックス以外のデータを取得してください。タグはカンマ[,]区切りで1度に複数指定可能です。
params = {'visualFeatures': 'Description,Objects'}| タグ | 説明 |
| Adult | 性的か、暴力的かの指数を表示 |
| Categories | Microsoft内で指定した分類の識別 |
| Objects | 画面内のオブジェクトを検出 |
| Color | アクセント・主要な色・画像が白黒か判別 |
| Description | 画像を文章で表現 |
| Faces | 顔が存在するか検出 |
| ImageType | 画像がクリップアートか線画かを検出 |
| Tags | 画像にタグをつける |
②取得したデータを加工し、表形式にまとめる
どのようにまとめるかは各自で自由に設定してください。
今回はこれで以上になります。次回のテーマは顔画像の感情認識です。感情認識は表情、音声、テキストなど様々なデータを対象としますが、その中でも表情(顔画像)を対象とし、画像認識の技術を応用して感情認識を行うのが顔画像の感情認識です。
最後までお読みいただきありがとうございました。それでは引き続き次回もよろしくお願いいたします。

